| 울타리 프로그램이 업데이트 되었습니다! 2.0 버전으로 업데이트 되었으며, 대대적인 디자인 업데이트가 있었습니다. 현재 다운로드 서버(드림위즈 서버)가 종료일을 앞두고 있어서, 프로그램을 업데이트 하지 않으신 분은 악성코드DB 및 최신 버전 정보를 받을 수 없습니다. 악성코드DB 가 최신이 아니면, 검색 능력이 현저하게 떨어지게 되므로, 반드시 업데이트를 하여 주시기 바랍니다. 울타리 { PROTECTS YOUR SYSTEM FROM MALWARE } 최신 버전 : 2.0, 업데이트 날짜 : 2008년 9월 2일 | ||
| ||
 [ 자세히 알아보기... ] [ 자세히 알아보기... ] |
분류 전체보기
- 울타리 2.0 업데이트!!! 2008.09.03 2
- 성공하는 개발자가 가져야할 7가지 습관 (3) 2008.08.14
- 성공하는 개발자가 가져야할 7 가지 습관 (2) 2008.08.07 1
- 어쩌다가... 2008.08.06 1
- 성공하는 개발자가 가져야할 7 가지 습관 (1) 2008.08.01 2
- Vista 에서 Low Level 권한으로 Process 를 생성시키는 방법 2008.06.28
- 위선 2008.06.16 1
- Pipe 를 사용한 Inter Process Communication. 2008.06.02 1
- korea 에 s/w 의 미래는 없다. 2008.06.02 1
- 이미지! 2008.05.31
울타리 2.0 업데이트!!!
2008. 9. 3. 18:29

성공하는 개발자가 가져야할 7가지 습관 (3)
2008. 8. 14. 11:53
성공하는 개발자가 가져야할 7 가지 습관
1. 설계
2. 디자인
3. 디버깅
4. 테스트
5. 리팩토링
6. 문제해결
7. 프로젝트 파일 관리
디버깅. 필자는 이 단어가 다소 어려운 이미지를 물씬 풍기고 있다고 생각한다. 마치 큰 벽처럼 프로젝트의 성공을 위해서는 이 디버깅이라는 벽을 뛰어넘어야만 하는 것 같은 생각이 들기도 한다. 하지만, 약간 다르게 생각을 해 보면, 사실은 디버깅이라는 것은 프로그램이 정상적으로 잘 작성되었다면, 아무것도 아닌 일이 될 수 도 있다. 디버깅이라는 것은 애초에 버그가 있어야 한다는 것인데, 이 버그가 없거나 매우 단순하다면 디버깅 작업도 단순할 수 밖에 없는 것이다. 모든 문제는 단순화시켜 놓으면 매우 단순하고 작아보인다. 하지만, 이것이 복합적으로 복잡하고 꼬여 있을 때에는 단순한 것들도 매우 커 보이는데, 사실은 이 문제들이 아주 작은 것들에서 비롯되어있고, 간단한 수정만으로 문제를 해결할 수 있는 경우도 참 많다.
하지만, 실제로 디버깅 과정은 고난과 역경의 연속이다. 때로는 상상할 수 없을 만큼 일들이 많이 꼬여 있어서, 더 이상 어떻게 손쓸 수 없는 경우도 있다. 필자가 경험한 프로젝트중 가장 디버깅이 어려웠던 프로그램은 오랜 시간동안 수많은 사람들의 손을 거친 프로그램이었는데, 이 프로그램의 일부 코드는 코드의 줄 수를 가지고 프로그램의 가치를 측정했던 오래전에 작성되었는지, 의미없는 코드의 반복까지 포함하고 있었던 프로그램이었다. 이 프로그램은 사실 디버깅을 하는 것 보다 실제로 프로그램을 새로 작성하는 것이 더 좋아보였다. 더군다나 이 프로그램의 디버깅이 더 어려웠던 이유는 이 프로그램은 어떤 기계의 데이터를 정리하고 그래프로 보여주는 프로그램이었는데, 필자의 이 기계에 대한 이해가 매우 부족했기 때문이다. 프로그램의 각 코드들을 이리저리 옮겨갈 수 는 있었지만, 과연 이 값이 두개로 유지될 필요가 있는 것인지에 대한 판단은 그 기계에 대한 이해없이는 어려웠기 때문이다.
이렇게 어려운 디버깅을 성공적으로 하기 위해서는 어떻게 해야 할까? 디버깅을 하는 일은 앞에서 말했다시피, 디버깅을 하는 프로그램이 작성된 과정이 매우 중요하기 때문에, 그 과정도 어떻게 딱 잘라서 말할 수 없는 복잡함이 있다. 그럼에도 불구하고 디버깅에서 가장 중요한 것은, 동일한 문제를 재현하는 것이다. '재현' 의 중요함은 독자들도 이미 수 많은 책들에서 읽었으리라 생각한다. 문제를 재현한다는 것은 그 문제에 대한 이해를 좀 더 높이는것이라고 볼 수 있다. 필자가 여기서 독자들에게 하고싶은 이야기는 단지 재현을 위한 재현이 아니라, 이 프로그램이 시스템의 어떤 부분들을 거치면서 문제를 만들어내는지를 항상 추적하면서 문제를 재현해야 한다는 것이다. 물론, 이러한 것을 정확하고 쉽게 하기 위해서는 수많은 경험이 필요하다. 여러가지 프로그램을 만들어보면서, 산전수전을 다 겪은 개발자는 어떤 문제가 발생하면, 자신의 경험에서 그 원인과 해결책을 금새 찾아낸다. 하지만, 모든 문제가 이렇게 해결되지는 않는다. 또한, 모든 개발자들이 이러한 능력을 얻을 수 는 없다. 그렇기 때문에 필수적으로 해야 하는 것이 바로 리버스 엔지니어링이다. 갑자기 리버스 엔지니어링에 대한 이야기가 나와서 놀란 독자들도 있을 것이다. 왜 갑자기 리버스 엔지니어링 이야기가 나왔는지 이제 좀 더 자세히 풀어보도록 하자.
이제 더 글을 읽기 전에 잠깐 디버깅을 했던 그 순간을 떠올려보자. 디버깅을 시작하는 이유는 프로그램에 문제가 있거나, 문제가 있을만한 부분을 확인하기 위함이다. 디버깅 툴을 켜는 순간 보통 '어디에서 문제가 발생했을까?' 라는 의문을 가지고 시작하게 된다. 그와 동시에 머리속에서는 프로그램이 동작하는 로직이 그려질 것이다. 디버깅을 하는 과정은 사실 리버스 엔지니어링을 하는 과정과 매우 유사하다. 단지 한가지 다른점이 있다면, 자신의 프로그램을 디버깅하는 프로그래머에게는 프로그램에 대한 소스와 그에 대한 정보들이 있지만, 리버스 엔지니어에게는 그러한 것이 없는 백지 상태에서 일이 시작된다는 것이다.
다른 일 보다도 프로그래밍에 대해서는 경험에 대한 것을 더 가치롭게 여긴다. 이론적인 지식도 매우 중요하지만, 실제로 프로그램을 작성하는 프로그래머에게 빠져서는 안될 덕목 중 하나가 바로 경험이기 때문이다. 세상 모든 일이 그렇겠지만, 책에서 정리한 이론에는 실제 세상(Real World)에 있는 많은 것들이 미화되어있거나 빠져있는 경우가 많다. 좀 더 이해하기 쉬운 예를 들자면, 게임을 만드는 게임 프로그래머가 자신이 만든 게임을 가장 잘 하는 것은 아니라는 것을 독자들은 알 고 있을 것이다. 그것은 게임을 하기 위해서는 게임에 대한 법칙(Rule)을 잘 아는 것만이 아니라, 그 법칙들이 서로 상호관계를 맺고 있는 여러가지 사항들에 대해서 잘 알 고 있어야 한다는 것이다. 더욱이 온라인 게임의 경우에는 이러한 논리에 의해서만 설명되는 것이 아닌, 사람과 사람 사이의 상호관계에 대한 내용도 포함되기 때문에, 게임의 법칙(Rule)을 아무리 잘 알 고 있다고 해도, 그 게임의 절대적인 고수가 될 수 없는 것이다. 이와 마찬가지로, 엄청난 이론으로 무장하고 있는 프로그래머라고 할 지라도, 실제로 프로그램을 작성하는데에는 문제가 많을 수 있다.
독자들이 실무에서 프로그램을 만들고 있고, 자신의 실력에 부족함을 느끼지 않는다면, 앞에서 필자가 말한 이론과 실제의 차이는 그리 큰 문제가 아니며, 관심거리도 아닐 것이다. 하지만, 애석하게도, 필자가 본 많은 프로그래머와 프로그래밍 관련 내용을 전공하는 많은 사람들은 자신이 알고 있는 것 만큼 프로그램을 잘 작성하지 못하는 사람들이 많았다. 무엇이 이러한 괴리를 만들어내는 것일까? 필자는 이 질문에 대한 해답을 기본적인 사고방식에서 찾고자 한다.
프로그래밍은 컴퓨터를 통해서 하는 일이다. 많은 사람들이 프로그래밍은 컴퓨터와 의사소통하는 것이라고 생각하고, 컴퓨터와만 잘 의사소통하면 된다고 생각한다. 하지만, 이러한 생각은 프로그래밍을 더 어렵게 만든다. 프로그래머가 컴퓨터와 의사소통을 하는데에 필요한 것은, 어셈블리 언어 혹은 프로그램이 만들어진 언어가 전부이다. 이 언어만 있으면 컴퓨터에게 무언가를 질문할 수 도 있고, 얻어낼 수 도 있다. 하지만, 많은 독자들이 알고 있겠지만, 이것만으로는 프로그램을 작성하는 것이 그리 순탄치만은 않다. 프로그램을 작성하면서 버그를 만났을 때, 버그를 도저히 찾을 수 없었던 경우가 있는지 모르겠다. 필자는 그런 경우가 꽤 많았다. 이러한 경우에, 많은 엔지니어들은 그러한 것을 기존에 존재하는 프로그래머들이 만들어 놓은 버그라고 생각한다. 왜냐하면, 그들이 알고 있는 논리와 기술적인 내용으로는 도저히 이해할 수 없기 때문이다. 하지만, 실제로 그 버그들의 정체는 나 자신의 문제인 경우가 대부분이다.
기존에 정상적으로 동작하고 있던 내용들이 자신의 프로그램으로 인하여 무언가 다른 동작을 하고 이상해 졌다면, 그것은 '나의 버그' 이다. 단순히, Windows 가 제공해주는 기능을 사용했는데 생각대로 동작하지 않는다고 해서 그것이 Windows 의 버그라고 할 수 는 없다. 실제로 Windows 는 그렇게 동작하도록 만들어졌고, 그렇게 동작하지 않는 것이 오히려 버그일 수 도 있는 것이다. 그렇다면, 이렇게 복잡하고 예측할 수 없는 환경에서 프로그램을 작성하기 위해서는 어떻게 해야 할까? 그것이 바로 리버스 엔지니어링을 배워야 하는 이유이다. 리버스 엔지니어링은 단순히 프로그램에 대하여 알아보는 것에서 그치는게 아니라, 프로그램을 만든 사람의 생각과 철학까지 리버싱 할 수 있어야 한다. 즉, 나 자신이 그 프로그램을 만든 사람의 입장이 되어보고, 왜 그렇게 만들었어야 했는지를 이해하여야 한다는 것이다. 그래야만, 그것에 따른 부가 효과(Side Effect)에 대해 이해하고, 그 부과 효과로인한 미묘한 동작들(실제로 많은 프로그래머들이 이해하지 못하고 버그라고 치부하는 것들)에 대한 이해와 올바른 사용을 할 수 있는 것이다. 필자는 리버스 엔지니어링을 하는 엔지니어는 마치 자연과학을 탐구하는 과학자와 같다고 생각한다. 왜냐하면, 자연과학자들은 우리에게 실제로 벌어지는 현상들을 토대로 하여 자연의 근본을 밝혀낸다. 그와 같이 리버스 엔지니어는 프로그램이 동작하는 실질적인 실행 과정을 통하여 프로그램의 근본 논리를 밝혀낸다. 모든 사물에 근본이 있듯이, 프로그램에도 근본적인 존재들이 있다. 프로그래머에게 있어서 가장 단순한 실행 상태인 CPU 의 명령어(Instruction)의 단계까지 내려가게 된다면, 그것을 기반으로 하여, 실질적인 프로그램의 논리를 파악할 수 있으며, 그렇게 되면, 사실상 프로그램의 원 소스 코드를 보고 있는 것과 별반 다를게 없는 형국이된다. 물론 이렇게 까지 자세하게 프로그램을 분석하는데에는 매우 오랜 시간과 노동이 필요하다. 하지만, 그것을 통해서 얻을 수 있는 것들은 결코 작지 않다.
우리가 살고 있는 세상은 엄청나게 작은 원자들이 모여서 분자를 이루고, 그것들이 다시 모여서 좀 더 큰 사물을 이루며, 그것이 다시 세상을, 지구를, 우주를 이루고 있다. 여기서 아주 작은 원자 하나가 바뀌게 된다면 어떻게 될까? 독자들이 알고 있는 것 처럼, 숱과 다이아몬드는 아주 작은 차이로부터 그 차이가 유래한다. 그것과 같이 근본적인 곳에서의 아주 작은 변화는, 실제하는 사물에서는 엄청나게 큰 변화를 초래한다. 이것은 프로그래밍에서도 동일하게 적용된다. 우리가 사용하고 있는 소프트웨어들은 수많은 계층 구조를 가지고 있다. 단순하게 생각했을 때에도, 이미 대부분의 소프트웨어는 Windows 라는 운영체제 아래에서 동작한다. 또한, 그 Windows 는 Kernel 이 존재하며, 이 Kernel 에 접근하기 위한 API 계층이 존재한다. 또, .NET Framework 등을 사용하는 프로그램의 경우에는 API 계층 아래에 .NET Framework 계층까지 존재한다. 프로그래머가 단순하게 생각하여 사용하는 가장 단순한 기능들도 이러한 무수히 많은 계층들을 거쳐서 실행되게 되는 것이다. 그렇기 때문에, 이 계층들에 대한 잘못된 이해는 실질적으로 엄청나게 잘못 만들어진 프로그램을 초래한다.
리버스 엔지니어링은 이러한 사소한 잘못된 이해들을 바로잡을 수 있는 방법이다. 물론, 잘못된 이해를 바로잡는 방법으로 정확한 레퍼런스를 보는것을 대안으로 주장하는 사람들도 있을 것이다. 하지만, 잘못된 편견을 가지고 있는 상태에서 정확한 레퍼런스를 본다고 하여, 그것이 올바르게 받아들여지지는 않는다. 마치, 지구는 둥글다라는 것을 실제로 보지 않고는 아무도 믿지 않는 것과 동일한 이치이다. 많은 프로그래머들이 오랜 시간 동안 프로그램을 작성하면서, 여러가지 시행착오를 겪고, 자신과 관련된 프로그램(e.g. 운영체제)에 대한 이해를 높여간다. 하지만, 정확한 분석 없이는 '그런것 같다' 라는 식의, 추측성 이해와 그로인한 임기응변성 테크닉만 늘어가게 된다. 예를 들면, 동기화 문제를 해결하는 방법은 여러가지가 있다. 하나는 정확한 논리를 사용하여 알맞은 동기화 객체를 사용하도록 하는 방법과, 동기화 문제는 주로 타이밍에 따라서 발생 빈도가 결정되므로, 타이밍을 좀 더 어긋나도록 하는 방법이 있다. 앞에서의 방법은 당연히 올바르고 정상적인 방법이지만, 후자는 임기응변식 방법이다. 이 방법은 마치 잘 해결되는 것 처럼 보이지만, 다른 사람에게 설명할 때에는, '그랬더니 잘 되더라' 라는 식의 두리뭉실한 설명밖에 해줄 수 없는 반쪽짜리 해결책이 된다. 또한, 이것은 해결책이라고 말할 수 도 없다. 왜냐하면, 타이밍이 달라지는 다른 PC, 특히 실행 속도가 차이나는 PC 에서 실행할 경우, 문제가 재발하거나 더 심각해질 수 있기 때문이다.
리버스 엔지니어링은 프로그램을 정확히 이해하는 과정이다. 정확히 이해한다는 것은, 말 그대로 '틀림이 없이' 이해한다는 것이다. 이 말은 참으로 혹독한 말이라서, 사실 정확하게 이해하기 위해서는 아예 그 프로그램의 소스코드를 읽을 수 있어야 한다. 하지만, 우리에게 소스코드는 주어지지 않는다. 그렇다면 어떻게 해야 할까? 프로그램을 정확히 이해하는 첫 걸음은 바로 프로그램을 오래 사용하여 익숙해지는 것이다. 아무리 뛰어난 프로그래머일 지라도, 익숙하지 못한 프로그램까지 잘 이해할 수 는 없다. 프로그램 자체를 한번도 보여주지 않고, '여기에서 A 버튼을 누르면 어떻게 될까요?' 라는 물음에는 절대 대답할 수 없다. 그렇기 때문에, 프로그램을 잘 이해하기 위해서 가장 먼저 해야 할 일은 프로그램에 익숙해지는 것 이다. 그러기 위해서는 먼저 프로그램을 많이 사용해보아야 한다. 특히, 입력에 대한 반응, 즉, 입력과 출력에 대한 부분을 집중해서 보아야 한다. 이러한 행동을 취했을 때, 이 프로그램의 반응이 어떤것인지를 알아야 한다. 필자가 말하는 리버스 엔지니어링은 프로그램의 모든 부분을 샅샅히 파해치는 것이 목적이 아니다. 앞에서 언급한 것과 같이, 훌륭한 프로그래머가 되기 위한 과정일 뿐이다. 즉, 다른 사람의 프로그램을 모두 해부해보는 것이 목적이 아니라, 나의 프로그램을 더 잘 만들기 위함이다. 그러기 위해서는 나의 프로그램이 상호작용하는 프로그램(대부분은 운영체제가 될 것이다)에 대하여 집중할 필요가 있다.
리버스 엔지니어링을 하면서, 버려야할 큰 것이 하나 있다. 바로, 통합 개발 환경(IDE)에 붙어있는 디버거를 사용하는 것이다. 그 이유는, 통합 개발 환경에 붙어있는 디버거는 운영체제의 좀 더 깊은 곳을 디버깅 하기에 적합하지 않기 때문이다. 물론, 적합하다고 하는 독자들도 있을 것이고, 실제로 그 환경이 더 편한 독자들도 있을 것이다. 하지만, 여기서 필자가 말하고자 하는 것은, 통합 개발환경에 붙어있는 디버거를 버리라는 것이 아니라, 통합 개발 환경에 있는 디버거를 사용하면서, 실제 라이브러리 내부의 코드들이나, API 함수 내부의 코드들을 디버깅하지 않으려는 자세를 버려야한다는 것이다. 실질적으로 많은 프로그래머들이 잘못 생각하는 것 중 하나는, API 는 완벽하다는 편견이다. 물론 API 는 대부분의 라이브러리나 함수들에 비해서 완벽하고 오류가 없다. 하지만, 이러한 것이 어떠한 환경에서도 절대로 API 는 문제를 발생시키지 않는다라는 이야기는 아니다. 특히 API 함수들 중, 다른 API 의 조합으로 만들어진 함수의 경우에는 다소 문제가 있는 경우가 더러 있다. 예를 들면,
성공하는 개발자가 가져야할 7 가지 습관 (2)
2008. 8. 7. 15:14
성공하는 개발자가 가져야할 7 가지 습관
1. 설계
2. 디자인
3. 디버깅
4. 테스트
5. 리팩토링
6. 문제해결
7. 프로젝트 파일 관리
다음으로 중요한 내용은 바로 디자인이다. 실질적으로 프로그램을 사용할 사람들이 만족할만한 프로그램을 작성하기 위해서는 좋은 디자인이 필요하다. 많은 개발자들이 이러한 디자인에 대하여 등한시 하는 경우가 있다. 물론, 이 글을 읽는 독자들 가운데는 '프로그램 만들기도 바빠 죽겠는데 그림까지 그리란 소리냐?' 라고 말할 수도 잇겠다. 필자가 여기서 말하고자 하는 내용은 '예쁘게' 만드는 디자인이 아니라, '사용하기 쉽게' 만드는 디자인이다. 사실, '예쁘게' 의 디자인은 익숙해지기 나름이다. 특정 분야의 프로그램(예를 들면 게임)이 아니라면, 디자인은 다소 부차적인 존재이다. 왜냐하면 대부분의 프로그램은 그 사용자들이 기능을 필요로 하기 때문에 사용하는 것이기 때문이다. 물론 게임과 같이 그 자체가 엔터테인먼트적인 성격을 가지고 있다면, 이는 디자인이 무시될 수 없을 것이다. 하지만, 대부분의 오피스 프로그램이나, 유틸리티 프로그램등은 디자인도 물론 중요하지만, 그 기능이 더 중요한 위치를 차지하고 있다. 이런 프로그램들에 있어서 디자인은 마치 '별것 아닌 것' 이라는 인상을 줄 수 도 있지만, 사실은 그렇지 않다. 우리가 모르는 디자인에서 오는 많은 것들은 가끔은 개발자를 소름끼치게 하는 경우도 있다.
디자인을 잘못하여 실패한 소프트웨어가 있을 수 있을까? 이렇게 부정적인 내용을 묻는 질문에는 '예' 라고 답하기보다는 '아니오' 로 답하기가 더 어렵다. 독자들도 예상했겠지만, 디자인을 잘못한 소프트웨어는 실패할 수 있다. 이제 그 자세한 이야기를 시작해보도록 하자.
디자인은 가장 기본적으로 프로그램과 사용자의 의사소통을 의미한다. 잘못된 디자인은 사용자들과의 의사 소통에 실패를 가져다준다. 그런 결과로 발생되는 '너무 사용하기 어려운 프로그램' 은, 곧 실패로 이어진다. 실제로 윈도우에 있는 여러가지 기능들은 매우 사용하기 어렵다. 사용되는 단어가 그 기능이 정확하게 무엇을 하는지를 알기 어렵게 만들고, 그 기능이 어디 있는지를 찾는것이 어렵기 때문에, 사용자는 모든 기능을 설정할 수 있는 프로그램을 가지고도, 실제로는 아무 기능도 사용할 수 없다. 잘못된 디자인을 가진 프로그램은 아무 기능도 없는 프로그램보다는 0.1% 정도 좋긴 하지만, 사실상 별 다를바가 없는 프로그램이다. 이와 비슷한 예를 들자면, 개발을 할 수 없는 일반 사용자들에게, 개발 프로그램(Visual Studio, Delphi, C++ Builder)을 사용하도록 하면, 그들은 실제로는 아무일도 할 수 없을 것이다. 이렇게 사용하기 어려운 프로그램은, 사실상 기능이 없는 것과 별반 다를게 없는 프로그램이 되어 버린다.
잘못된 디자인은 프로그램을 사용할 수 없게 만들어 버리기도 하지만, 사용하기 위험한 프로그램으로 만들기도 한다. 한 예를 들어보자. 수치를 입력하기 위해서는 여러가지 방법이 있다. 0 에서 100 까지의 값을 입력 받기 위해서는, 슬라이드 컨트롤을 사용할 수 도 있을 것이고, 에디트박스를 사용할 수 도 있다. 일반적으로 프로그래머들은 자신들의 입장에서 생각하기 때문에, 슬라이드 컨트롤보다 에디트박스를 선호한다. 하지만, 에디트 박스는 여러가지 위험을 내포한다. 가장 큰 위험은 바로 입력 할 수 있는 방법이 무궁무진하여 진다는 것이다. 에디트박스에는 문자가 들어갈 수 있는데, 실제로 프로그램이 얻고자 하는 데이터는 '숫자' 형태이다. 이런식으로 디자인된 프로그램은 사용하기도 불편할 뿐만 아니라, 프로그램의 안정성 자체를 디자인 단계에서 해치게 되는 문제를 낳게 된다. 많은 보안 관련 서적에 항상 나오는 말이지만, 사용자의 입력을 절대로 믿지 않는 것인 보안의 첫걸음이다. 디자인은 프로그램과 사용자가 만나는 창구이면서, 사용자가 실제로 값을 입력하는 프로그램의 최전선이다. 이 최전선에서의 방어는 안전한 프로그램을 만들기 위한 가장 중요한 부분 중 하나이다.
[필자 메모]--------------------------------------------------------------------
어떤 일이든 문제가 한번 발생한 이후에, 그것을 처리하기 위한 비용은, 그 문제를 발생시키기 전의 비용보다 훨씬 크다. IBM 은 Microsoft 에 OS 시장을 빼앗긴 이후로 그 시장을 되찾기 위해서 어마어마한 비용을 들였지만, 결국 다시 뺴앗아오지 못하였다. 보안도 마찬가지이다. 사소한 실수로 인하여 보안의 허점이 발생한 프로그램은 어마어마한 피해를 불러일으킬 수 도 있다. 사실, 어떻게 프로그램을 만든다고 할 지라도, 크래커를 완전히 막을 수 는 없다. 크래커에게 바이너리 파일은 소스파일과 같기 때문에, 크래커에게 공격을 하는 것은, 프로그래머가 새로운 기능을 프로그램에 추가하는 것과 같다. 그렇기 때문에, 초기에 아무리 노력한다고 해서 완전히 안전한 프로그램을 만들 수 있는 것은 아니다. 하지만, 불가능하다고 손을 놓는 것이 아니라, 최대한 크래커에게 찾을 수 있는 방법을 없애는 것이 좀 더 안전하고 뛰어난 프로그램을 만드는 개발자가 해야 할 일이다.
[필자 메모]--------------------------------------------------------------------
디자인에 대하여 좀 더 이야기해보도록 하자. 디자인은 단지 외형적으로 드러나는 모양에서만 그치지 않는다. 소스 내부의 인터페이스 조차 디자인이라고 할 수 있다. 사실 앞에서 말했던, 보안성이 높은 프로그램을 만들기 위한 디자인에 대한 이야기는 소스 내부의 인터페이스에서의 디자인에서 언급할 내용과 다소 유사한 면이 없지 않아 있다. 사용자가 직접 사용하는 프로그램 인터페이스에서 사용자의 악의적인 입력이나 잘못된 입력을 걸러낼 수 있어야 하는 것 처럼, 프로그램 내부적으로도 그러한 문제를 해결할 수 있는 인터페이스의 가이드 라인이 필요하다. 이는 앞에서 필자가 이미 언급했던 것 처럼, 프로그램의 코드를 사용하는 개발자도, 또 다른 사용자의 한 형태라고 볼 수 있기 때문이다. 자신이 만들었다고 해서 오랜 시간이 지난 이후에도 자신의 소스를 100% 확실하게 사용할 수 있다는 보장은 없다. 하물며, 다른 사람의 소스를 사용하는 개발자의 경우에는 이러한 현상이 더 심할 것이다. 그렇기 때문에, 프로그램 내부의 인터페이스 디자인에 신경을 쓰지 않게 되면, 스스로 모듈들을 통합하면서 버그를 만들어내는 모습을 보게 될 것이다. 필자가 항상 다른 사람들에게 인터페이스에 관련된 이야기를 하면서 예로 드는 코드가 있다. 바로 <리스트1> 과 <리스트 2> 의 코드이다.
[리스트 1]-----------------------------------------------------
CInfoDialog dlgInfo;
if(dlgInfo.DoModal()==IDOK){
Data1 = dlgInfo.GetResult1();
Data2 = dlgInfo.GetResult2();
Data3 = dlgInfo.GetResult3();
}
----------------------------------------------------------
[리스트 2]-----------------------------------------------------
CInfoDialog dlgInfo;
if(dlgInfo.DoModal()==IDOK){
dlgInfo.GetResult(Data1, Data2, Data3);
}
----------------------------------------------------------
<리스트 1> 과 <리스트2> 의 코드는 모두 어떤 다이얼로그에서 입력된 값의 결과를 가져오는 코드이다. 이러한 내용은 간단히 소스코드의 단어들만 보아도 알 수 있을 것이다. 하지만, 두개의 코드는 목적은 같지만 형태는 다르다. 과연 어느것이 더 좋은것일까? 여러가지 의견이 있을 수 있겠지만, 필자의 생각으로는 <리스트 2>쪽의 코드가 더 좋다는 것에 손을 들어주고 싶다. 왜냐하면, 혹시라도 나중에 반환값이 하나 더 늘어났을 경우에, <리스트 1>의 경우에는 다이얼로그의 GetResult4() 함수를 추가 하였더라도, 실제로 호출하지 않는 경우가 발생할 수 있으며, 이 경우에 에러가 발생하지 않아서 프로그래머가 실수 할 수 있는 경우가 많아지지만, <리스트2> 의 경우에는, GetResult 함수의 파라메터를 수정하게 되면, 자동적으로 GetResult 를 호출하는 부분에서, 파라메터를 얻어오지 않을 경우에 에러가 발생하기 때문에, 실수를 할 확률이 더 줄어들게 되기 때문이다.
또, 이러한 유사한 것으로 전달하는 데이터의 형태가 어떤것인지도 중요하다. 주로 많이 실수하는 것 중 하나는, String 데이터를 null 값 없이 전달한다거나, unsigned 데이터 형을 signed 데이터 형으로 입력 받는다거나 하는 것들이다. 이러한 것들은 아주 사소해 보이지만, 실제로는 큰 문제를 일으킬 수 있는 위험한 것들이다.
[필자 메모]--------------------------------------------------------------------
쉬어가는 의미에서 간단한 코드에 대한 이야기를 해 볼까 한다. 꽤 오래된 이야기인데, 아무 의미 없는 if 구문에 대한 내용이 이슈가 된 적이 있었다. 바로 ' if('^' == '^') { ' 로 시작하는 if 구문이었는데, 독자들도 이해하겠지만, 이 코드는 항상 TRUE 인 조건을 가지고 있기 때문에, if 구문안에 있는 것이 무조건 실행된다. 그렇다면 과연 이런 코드는 왜 있었을까? 그것은 바로 해당 코드안의 내용을 좀 더 강조하기 위한 것이다. 이러한 방법은 개발자마다 다소 다른 방법을 가지고 있다. 필자의 경우에는 #pragma message 를 주로 사용하는 편이다. 이것을 사용하여 혹시라도 다음 소스코드를 수정할 때, 실수할 만한 내용들을 소스 코드안에 넣어버린다. 이런식으로 소스 코드 안에 개발자들이 이해할 수 있는 어떤 기호들을 넣어두는 것은 참으로 유용하다. 물론 문서를 그때그때 찾아보면서 정확한 History 와 문제점을 파악하면서 꼼꼼히 개발하는 것이 가장 정석이겠지만, 이러한 탁상공론이야 굳이 말하지 않아도 불가능하다는 것을 독자들은 이미 알고있을 것이니까...
----------------------------------------------------------
이렇게 디자인은, 간단하게 프로그램과 사용자의 의사소통의 장이 되면서, 실제로는 개발자와 개발자의 의사소통의 장이 되기도 한다. 의사소통에 실패한 프로젝트와 프로그램은 실제로 아무도 사용할 수 없는 애물단지가 되어버린다. 그 어떤 누구라도 자신이 애써서 개발한 프로그램이 자신이나 다른 누군가에게 이러한 취급을 받는 다는 것은 가슴아픈일일 것이라고 생각한다. 그렇기 때문에, 디자인은 어떻게든 완성될 프로그램에 있어서, 그 프로그램의 품질에 가장 큰 영향을 주는 것이라고 할 수 있다. 기능이 아무리 많고 잘 동작하는 프로그램이라고 할 지라도, 그 기능이 완전하지 못하고, 그 기능을 사용자가 실제로 사용할 수 없다면, 이것은 그림의 떡이 되어버릴 것이다. 이러한 이유가 필자가 디버깅과 같은 기타 내용보다도 디자인에 대한 내용을 좀 더 앞에 둔 이유이다. 디버깅은 프로그램 개발 프로세스에서 매우 중요한 내용이지만, 이것은 제품이 정상적으로 나오고 사용자들의 요구를 맞추었을 경우의 일이다. 아무도 사용할 수 도 없는 기능이 완벽히 동작한다고 과연 그것을 누가 알아줄수 있을까?
어쩌다가...
2008. 8. 6. 15:04
성공하는 개발자가 가져야할 7 가지 습관 (1)
2008. 8. 1. 10:42
성공하는 개발자가 가져야할 7 가지 습관
1. 설계
2. 디자인
3. 디버깅
4. 테스트
5. 리팩토링
6. 문제해결
7. 프로젝트 파일 관리
개발자는 단지 프로그램을 작성하기 위한 사람이 아니다. 개발자는 한 제품을 성공적으로 개발하기 위한 사람이다. 그렇기 때문에, 단순히 개별 모듈만을 작업하는 '코더' 와는 그 목표가 확연히 다르다. 가장 능력있는 개발자는 그가 개발하기 시작한 제품이 절대로 실패하지 않는 개발자이다. 물론, 이러한 성공률을 높이기 위해서 '아예 제품을 만들지 않는' 방법을 사용하지 않고 말이다.
여기까지만 읽은 독자들 중, 숨이 턱까지 찬 독자도 있을 것이다. 그럴수 있다. 앞에서 말한 제품 개발에 실패하지 않는 사람은 아무도 없기 때문이다. 개발자라면, 누구나 자신이 애써 만든 제품이 시장에 나가 성공하길 바랄 것이고, 그렇게 하기 위해서는 참으로 많은 난관이 존재한다. 제품을 하나 새롭게 만든다고 생각해보자. 가장 먼저 여러가지 제품들에 대한 벤치마킹을 한 후, 프로그램을 설계하고, 개발을 시작한다. 그리고, 개발된 제품을 디버깅하고, 데드라인에 맞추어 개발을 완료한다. 간단히 말로 적은 이 한줄이, 실제로 개발하는 사람의 입장에서는 피마르는 몇개월이된다. 아니, 사실 여기까지만이라도 정상적으로 완료가 되었다면, 이 프로젝트는 반은 성공한 프로젝트라고 할 수 있다. 하지만, 이 과정이 끝났더라도 더 많은 난관이 남아있다. 실제 제품이 시장에 나가서 성공하기 위해서는 시장에 배포된 이후의 사후처리도 매우 중요하다. 또한, 가장 중요한 시장에 수요와 요구에 맞게 변화하는 제품을 설계하는 것이 매우 중요한 일이다.
이러한 많은 난관을 잘 해쳐나가기 위해서, 개발자가 가져야할 덕목은 참으로 많다. 하지만, 필자가 본 많은 개발자들은 자신이 가진 습관과 일반적인 편견으로 많은 것들을 놓치고 있는 경우가 많았다. 물론, 필자도 그것들과 똑같은 실수를 하는 경우가 많이 있다. 무엇이든 자신이 알고 있는 것 보다는, 실제로 경험해보고 실패하면서 몸에 익힌 경험이 더 값진 법이기 때문이다. 이 글을 읽은 독자들이, 이 글에서 전하고자 하는 내용을 모두 체화시킬 수 는 없겠지만, 개발을 하면서 비슷한 문제에 봉착했을때, 이 글에 씌여진 필자와 많은 사람들의 경험이 도움이 되었으면 하는 바람이다.
개발자가 가져야할 7가지 습관 가운데 가장 중요한것은 설계이다. 설계 없는 프로그램은 사공이 많은 배가 되어, 산으로 올라갈 뿐이다. 물론, 프로젝트를 자신 혼자만 한다고 하면, 이 부분은 크게 문제가 되지 않는다. 어찌되었건 간에 사공이 물리적으로하는 한명이기 때문이다. 그렇다고 '난 혼자 개발하기 때문에 필요없어' 라고 말하는 개발자가 있다면, 잠깐 멈춰서서 글을 좀 더 읽어보기를 바란다. 물리적으로 단 한명은 개발자가 개발하는 프로젝트라고 할 지라도, 논리적으로는 여러명일 수 있다. 무슨 소리지? 라고 갸우뚱 하는 독자들을 위해서 좀 더 설명하자면, 사람은 시간이 지남에 따라서 참으로 많은 것이 바뀐다. 여러가지 경험에 따라서 생각도 바뀔 수 있고, 오늘 읽었던 책에 대한 기억이 오늘은 선명하겠지만, 내일은 더 흐릿해질 수 도 있는 것이다. 또한, 여러가지 외부 상황(개인적인 사정 등)에 따라서 더 안좋아질 수 도 있다. 이러한 많은 것들을 따져 보았을 때, 오늘 A 방향으로 만들자고 결정한 내용에 대하여, 다음날 갑자기 B 방향으로 가는게 더 좋아보일 수 도 있다는 것이다. 설계는 이러한 것을 방지하기 위한 일종의 확인과정이다.
설계를 철저하게 하면, 코드가 복잡해질 일 도 없고, 리팩토링도 하지 않아도 된다는 그러한 말도 있다. 필자가 말하고자 하는 설계는 그정도로 철저하게 하라는 것은 아니다. 물론, 설계를 완벽하게 한다면 코드가 복잡해질 일도, 리팩토링도 하지 않아도 된다. 설계서대로만 개발하게 되면, 더 이상 수정할 것도 없는 완벽한 프로젝트가 될 수 도 있다. 하지만, 이것이 가능하기 위해서는 실패한 설계가 필요하며, 설계가 실패하였다는 것을 증명하기 위해서는 사실상 실질적인 구현과정과 실패과정이 있어야 한다. 논리학적으로 어떤 명제가 잘못되었다는 것을 밝히기 위해서는 단지 그 명제가 맞지 않는 단 하나의 예시만 들면 되지만, 그 명제가 맞다는 것을 증명하는 것은 쉽지가 않다. 또한, 이에 대한 완벽한 프로세스가 존재하지 않기 때문에, 사실상 이것은 불가능하다고 할 수 있다. 그렇기 때문에, 설계를 완벽하게 하기 위해서는 일단 설계서대로 개발하는 과정을 여러번 겪어서 실패하는 수 밖에 없다는 것이다. 하지만, 사실상 이런식으로 소모적으로 설계 및 실패를 반복하는것은 불가능하다. 그에 따른 추가 비용이 너무 많이 들기 때문이다. 실패하는 프로젝트는 실제 제품으로 시장에 판매될 수 없기 때문에, 그 동안의 노력과 시간은 그대로 투자금액이 되어버린다. 이런 문제점을 해소하기 위해서 많은 개발자들이 조언하는 것은 단위별로 이러한 과정을 반복하라는 것이다. 단위테스트는 이러한 비용을 최소화시켜주며, 단위테스트가 된 각 모듈은 실제로 제품으로 합쳐졌을때 최소한의 문제를 발생시키도록 도와준다. 요즈음은 개발자들이 설계나 디버깅, 테스트 등에 많은 관심이 있어서 이러한 단위테스트들은 이미 익숙하고 잘 진행하고 있을거라고 생각하지만, 혹시라도 아직도 단위테스트를 하지 않고 있는 독자들이 있다면, 오늘부터라도 단위테스트를 하는 습관을 길러 보도록 하는게 좋을 것 같다.
설계는 코딩하지 않고 제품을 하나 만들어보는 행위이다. 물론, 실제로 코딩하지 않기 때문에, 실제 개발과정에서 겪는 많은 문제점들을 볼 수 없지만, 대략적인 제품 전체의 논리와 통합의 당위성등은 판단할 수 있다. 또한, 개발자의 입장에서 설계가 없는 프로그램은 어디로 갈 지 모르는 배에 탄 선원이 되는 것이지만, 설계가 있는 경우에는, 목적지가 뚜렷하게 정해진 배의 선원이 되는 것이므로, 자신이 하는 일에 대한 가치판단에서 자유로워 질 수 있다는 장점이 있다. 이 말이 다소 와닿지 않는 독자들을 위한 간단한 예를 들게 된다면, 설계를 하지 않고 프로그램을 작성하는 개발자는 새로운 버튼이 하나 추가될때마다, 이 버튼에 대한 기능을 트레이 아이콘 메뉴와 메인 메뉴, 그리고 다른 다이얼로그 박스의 버튼으로 추가해야할 것인지를 매번 고민해야 한다. 이는 매우 소소한 것처럼 보이지만, 이 소소한 것들에 대하여 매번 새로운 가치판단을 한다고 한다면, 프로그램의 일관성은 이미 없어져있을 것이다. 이러한 일관성이 없는 것의 대표적인 예는 '오픈소스' 프로그램이다. 필자는 개인적으로 오픈소스에 대한 정신은 찬성하지만, 서로 모르는 다수의 프로그래머가 추진하는 오픈소스 프로그램의 소스코드의 질(Quaility)에 대해서는 부정적인 입장이다. 서로 모르는 다수의 프로그래머는 서로 다른 가치판단을 내릴 수 밖에 없기 때문에, 프로그램이 일관성이 있게 진행되는 것이 여간 어려운 일이 아니다. 그러므로, 실제로 그러한 프로그램들의 소스 코드를 보면, A 소스코드와 B 소스코드가 완전히 다른 스타일로 작성되어 있어서 파악하기가 힘든 경우가 많다. 이런 경우가 여러번 반복되면 프로그램을 이어서 작성하는데 필요한 노력은 기하 급수적으로 증가한다. 곧, 얼마가지않아 그 프로그램은 더 이상 업데이트를 하는 것 보다 아예 처음부터 새로 만드는 것이 빠른 프로그램이 될 수 도 있다. 물론, 현실적으로 이러한 문제점을 가지고 있지만, 실제로 이러한 상태로 출시되는 제품도 많이 있다. 아마 현업에 종사하고 있는 많은 개발자들은 이 말에 깊은 공감을 느낄 것이다. 물론, 이러한 현실을 탓하고자 하는 것은 아니다. 이러한 현실을 알고 있는 개발자들은 이러한 일이 다시 발생하지 않도록, 최대한 노력하여야 한다는것이 필자의 생각이며, 이것은 누구를 위한 것도 아닌 바로 자기 자신을 위한 일이다. 또, 이러한 현실을 모르고 있던 개발자들은 이러한 것을 인정하고 나는 그러한 좋지 않은 관행을 되풀이 하지 않아야 겠다는 생각을 하여야 하겠다.
앞에서는 설계를 철저하게 하여야 한다는 말을 했는데, 사실 설계를 완벽하게 할 수 는 없다. 앞에서 말한 것 처럼, 이미 실제 제품을 만들어서 실패한 경우에는 그렇게 할 수 있지만, 사실상 업무에서는 '처음' 으로 설계하여, 그것을 성공으로 이끌어야 하기 때문에, 설계는 항상 성공하기 어려운 과제이다. 그렇기 때문에, 개발자는 설계에서 모든 것을 다 잡을 수 없으며, 그렇게 해서도 안된다. 즉, 설계는 완벽할 수 없기 때문에, 완벽하려는 욕심을 버리라는 것이다. '아니 앞에서는 설계가 무척 중요하다고 해놓고 이제와서 대충 하라는 말인가?' 라고 생각할 수 도 있겠다. 맞다. 하지만, 대충 하라는 말은 아니다. 설계는 완벽할 수록 좋지만, 모든 일에는 일을 처리할 수 있는 제한 시간이 있다. 그 제한 시간 안에 최대한 충실하게 하면 된다는 것이다. 다만, 독자들의 경험을 살려, 문제가 될 수 있는 부분만 정확하게 짚어가면서 설계를 하면 된다. 설계를 아무리 완벽하게 했더라도, 그 설계는 항상 바뀔 수 있다. 그 설계가 아무리 완벽할지라도, 실제로 제품을 사용하는 사용자의 요구사항이 바뀌게 된다면 설계도 바뀔 수 밖에 없기 때문이다. 그렇기 때문에 설계는 모든 조건을 다 만족시킬 수 없으며, 모든 문제를 해결할 수 없다. 단, 문제가 커지는 일을 방지할 수 있을 뿐이다. 그러한 이유로 개발자가 가져야할 7가지 습관 중 가장 먼저 나온것이 바로 이 '설계' 의 습관이다.
설계에 대한 또 다른 잘못된 생각을 하나 더 이야기 하자면, 설계를 중요하다고 생각하는 많은 사람들은, 설계를 하지 않고 코딩을 시작하는 프로그래머들을 다소 비하하곤 한다. 하지만, 필자의 생각은 다소 다르다. 설계는 물론 중요하고 프로젝트 시작전에 이루어져야 하지만, 아주 간단한 프로그램에까지 이러한 과정을 거치도록 강요하는 것은 올바르지 않다. 프로젝트의 미래를 예측할 수 있을 만큼 간단한 프로젝트에까지 무조건 설계를 할 필요는 없다. 예를 들면, 프로젝트에서 잠깐 필요한 디버깅용 소품 프로그램까지 설계를 해야 한다면, 이는 설계를 위한 설계가 될 것이다. 또한, 이렇게 작은 프로젝트가 아니더라도, 코딩 하는 것 자체가 설계와 위반되는 것은 아니다. 작은 단위의 프로젝트를 설계 이전에 직접 구현해 보는 것은, 좀 더 좋은 설계에 밑거름이 된다. 또한, 작은 실패는 큰 실패를 막을 수 있는 방패가 되어주고, 작은 성공을 쌓아가면서 큰 성공을 하게 해 주는 밑거름이 되어준다. 단위 테스트를 거친 작은 모듈들은 그것을 통합하더라도 큰 문제가 없기 때문이다. 이 내용이 실제로 와닿지 않는 독자들은 독자들이 사용하는 각종 플랫폼의 API 를 생각해보면 될 것이다. 대부분의 개발자들이 사용하는 API 들은 고도의 테스트를 거쳐서 릴리즈된다. 그렇기 때문에, 그것을 사용하여 만든 프로그램도 문제가 없이 동작하는 것이다. 혹자들은 특정 OS 에서 발생하는 블루스크린이나 시스템 실패(System Fault)를 가지고, 그 시스템 자체의 안정성을 의심하기도 하지만, 사실상 이것들은 시스템의 문제라기보다는 그 시스템에서 동작하는 수없이 많은 어플리케이션들의 문제이며, 이 어플리케이션은 안정성이 확보되지 않은 채로 시장에 출시되기 때문에 발생하는 문제이다. 이처럼, 단위 테스트를 철저하게 거친 모듈들은 그것을 다시 재 조합하더라도 문제가 발생하지 않는다. 이렇게 작은 단위로 나누어서 각 모듈의 안정성을 확보하고 그것을 전체 프로그램의 안정성으로 이어가는 방법은 적은 노력으로 큰 문제를 해결할 수 있게 하여 준다.
다소 장황한 이야기가 되었던 것 같다. 이야기를 정리해보자면, 설계는 꼭 필요하고 최대한 노력을 기울여야 하는 것이지만, 실질적으로 설계에 투자할 수 있는 시간은 무한정 주어지지 않는다. 그런 문제를 해결하기 위해서, 자신에게 주어진 시간에 최대한 설계를 철저하기 위한 계획을 만들어야 한다. 물론, 이 계획 조차도 바뀔 수 있다. 하지만 한가지 필자가 조언해주고 싶은 내용은, 예상보다 계획된 시간이 점점 줄어들고 있다면 실제 구현보다는 설계에 좀 더 많은 시간을 투자하는것이 좋다는 것이다. 또, 설계를 무조건 철저하게 하여야 한다는 생각으로, 무한정 설계에 시간을 투자하게 되면, 실제로는 구현할 수 없는, 너무 큰 프로그램이 될 수 도 있다. 이에 대한 것은 개발자 자신이 잘 조절하여야 하는데, 이것은 작은 모듈들에 대한 설계를 여러번 해 보는 것으로 익숙해질 수 있다.
Vista 에서 Low Level 권한으로 Process 를 생성시키는 방법
2008. 6. 28. 00:20
BOOL bRet;
HANDLE hToken;
HANDLE hNewToken;
// Notepad is used as an example
WCHAR wszProcessName[MAX_PATH] = L"C:\\Windows\\System32\\Notepad.exe";
// Low integrity SID
WCHAR wszIntegritySid[20] = L"S-1-16-4096";
PSID pIntegritySid = NULL;
TOKEN_MANDATORY_LABEL TIL = {0};
PROCESS_INFORMATION ProcInfo = {0};
STARTUPINFO StartupInfo = {0};
ULONG ExitCode = 0;
if (OpenProcessToken(GetCurrentProcess(),MAXIMUM_ALLOWED, &hToken))
{
if (DuplicateTokenEx(hToken, MAXIMUM_ALLOWED, NULL,
SecurityImpersonation, TokenPrimary, &hNewToken))
{
if (ConvertStringSidToSid(wszIntegritySid, &pIntegritySid))
{
TIL.Label.Attributes = SE_GROUP_INTEGRITY;
TIL.Label.Sid = pIntegritySid;
// Set the process integrity level
if (SetTokenInformation(hNewToken, TokenIntegrityLevel, &TIL,
sizeof(TOKEN_MANDATORY_LABEL) + GetLengthSid(pIntegritySid)))
{
// Create the new process at Low/High integrity
bRet = CreateProcessAsUser(hNewToken, NULL,
wszProcessName, NULL, NULL, FALSE,
0, NULL, NULL, &StartupInfo, &ProcInfo);
}
LocalFree(pIntegritySid);
}
CloseHandle(hNewToken);
}
CloseHandle(hToken);
위선
2008. 6. 16. 22:03
1. 항상 느끼는 것 중 하나.
무언가 말을 하기 전에는 나 자신이 어떤 사람인지, 어떤 행동을 하는지 보아야 한다.
누군가의 잘잘못이나 가치를 따지기 전에는 자신의 수준을 인정하거나, 남을 폄하하지 않는게 좋다.
2. 한국에서 software 가 성공할 수 없는 이유 라는 글은 가끔씩 웹 서핑을 할 때마다 눈에 들어와서 보곤 하는 글 중 하나이다.
하지만, 항상 그 글을 볼 때마다 더 나아진게 없는 현실과, 자신의 처지를 보곤 한다.
이 나라에 software 는 힘들다.
그것의 선봉장에는 무분별한 IT 진흥 정책으로 인한 인력 인플레이션이 있었다고 생각한다.
그래서 나는 김대중 전 대통령의 IT 진흥 정책만은 좋아하지 않는다.
무언가 말을 하기 전에는 나 자신이 어떤 사람인지, 어떤 행동을 하는지 보아야 한다.
누군가의 잘잘못이나 가치를 따지기 전에는 자신의 수준을 인정하거나, 남을 폄하하지 않는게 좋다.
2. 한국에서 software 가 성공할 수 없는 이유 라는 글은 가끔씩 웹 서핑을 할 때마다 눈에 들어와서 보곤 하는 글 중 하나이다.
하지만, 항상 그 글을 볼 때마다 더 나아진게 없는 현실과, 자신의 처지를 보곤 한다.
이 나라에 software 는 힘들다.
그것의 선봉장에는 무분별한 IT 진흥 정책으로 인한 인력 인플레이션이 있었다고 생각한다.
그래서 나는 김대중 전 대통령의 IT 진흥 정책만은 좋아하지 않는다.
Pipe 를 사용한 Inter Process Communication.
2008. 6. 2. 23:13
 invalid-file
invalid-file
소스 파일 다운로드
이러한 제약 사항들은 운영체제나 사용자의 보안성에 좋은 영향을 주지만, 시스템 유틸리티나 보안 소프트웨어를 개발하는 사람들에게 있어서는 매우 치명적인 일이 될 수 밖에 없다.
하지만, Windows Vista 에서도, 시스템 유틸리티나 보안 소프트웨어를 개발하는 프로그래머들을 위한 길을 아예 없애버린것은 아니다. 단지, 좀 더 명확한 정책을 따르도록 변경된 것일 뿐이다. 일반적으로 Windows XP 혹은 그 이전에는 '서비스 프로그램' 이 그다지 많은 호응을 받지 못했다. 왜냐하면, 서비스 프로그램은 만들기도 힘들고, 관리도 귀찮았기 때문이다. 하지만, Windows Vista 와 UAC 가 등장하면서 부터, 서비스 프로그램은, 관리자 권한 프로그램을 실행하고자 할 때 가장 안전하고 간편한 방법 중 하나이다. 이번에는 이러한 서비스 프로그램을 사용할 때 가장 문제가 되는 Inter Process Communcation 에 대하여 알아볼 것이다.
먼저, IPC 를 하는 방법은 여러가지가 있다. WM_COPYDATA 를 사용하는 방법, Shared Memory 를 사용하는 방법, Pipe 를 사용하는 방법, Socket 을 사용하는 방법...등 매우 다양한 IPC 방법들이 존재한다. 하지만, 여기서 다루고자 하는 것은 Pipe 을 사용하는 방식이다. 왜 이 방법을 택해야 하는 걸까? 그에 대한 답변은 매우 간단하다. 먼저, 메시지를 주고 받는 방법은 서비스 프로그램과 IPC 를 할 대상 프로그램과의 Desktop 이 다른 경우 사용할 수 없다. Shared Memory 의 경우도 앞의 경우와 같은 문제를 가지고 있는데, Session 이 다른 경우, 다른 Session 의 Shared Memory에 접근할 수 없다. Socket의 경우에는 가능은 하지만, 단순한 IPC 를 위해서 Socket 을 사용하는 것은, 구덩이를 파기 위해 포크레인을 동원하는 것과 같다.
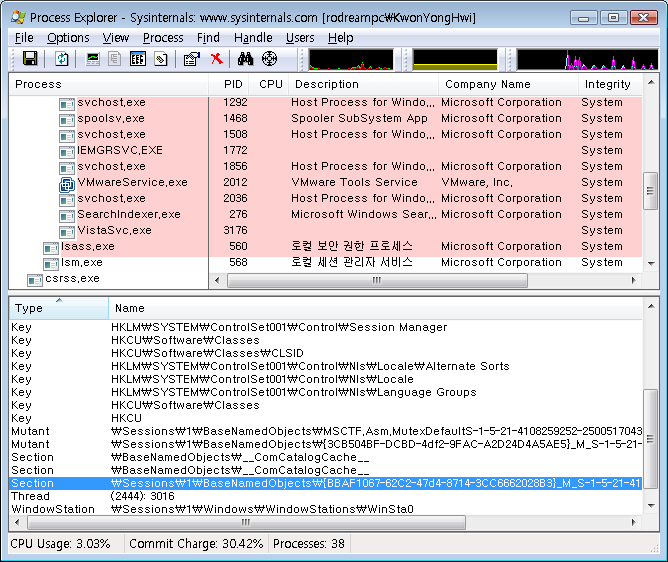
[그림1] Shared Memory (Section) 는 Session 마다 개별적으로 이름을 가지게 되며(e.g. \Session\1\이름) 각 Session 은 다른 Session 의 Section 을 침범할 수 없다.
그래서 결국 선택된 것이 Pipe 이다. Pipe 는 간단한 IPC 를 구현하는데 유효하며, 프로그램이 실행되는 Desktop 이나 계정에 상관없이, 공유가 가능하다.
Pipe 는 CreateNamedPipe 함수와 ConnectNamedPipe 함수를 통하여 초기화 작업을 진행한다. 그 이후로는 ReadFile 과 WriteFile 을 사용하여 데이터에 접근하게 된다.
CPipeServer
CPipeServer 는 필자가 비스타에서 서비스 프로그램과 IPC 를 하기 위하여 만든 Pipe Server 클래스 이다. 이 클래스는 StartPipeServer 함수를 가지고 있으며, 이 함수를 호출하면, 서버 파이프를 초기화 하고, 클라이언트의 접속을 대기하는 쓰레드를 생성한다.
앞에서 설명한 대로라면, Pipe 는 Vista 에서 쉽게 동작하는 것 처럼 보였지만, 실제로는 한가지 더 신경써줘야 할 것이 있다. 바로 Pipe 의 권한이다. Vista 의 UAC 는 프로그램마다 권한을 가지도록 하였으며, 낮은 권한의 프로그램이 높은 권한의 프로그램이 가지고 있는 리소스에 접근할 수 없도록 제한하고 있다. 그래서 필요한 것이, Pipe 의 권한을 조절하는 것이다.
위의 코드는 Pipe 를 생성할 때, Security Attribute 속성을 지정하여, 낮은 권한의 프로그램에서도 해당 Pipe 를 열 수 있도록 허용하는 코드이다.
BYTE sd[SECURITY_DESCRIPTOR_MIN_LENGTH];
SECURITY_ATTRIBUTES sa;
sa.nLength = sizeof(sa);
sa.bInheritHandle = TRUE;
sa.lpSecurityDescriptor = &sd;
InitializeSecurityDescriptor(&sd, SECURITY_DESCRIPTOR_REVISION);
SetSecurityDescriptorDacl(&sd, TRUE, (PACL) 0, FALSE);
hPipe = CreateNamedPipe(
pInfo->szPipeName, // pipe name
PIPE_ACCESS_DUPLEX, // read/write access
PIPE_TYPE_MESSAGE | // message type pipe
PIPE_READMODE_MESSAGE | // message-read mode
PIPE_WAIT, // blocking mode
PIPE_UNLIMITED_INSTANCES, // max. instances
BUFSIZE, // output buffer size
BUFSIZE, // input buffer size
0, // client time-out
&sa); // default security attribute
이렇게 만들어진 Pipe 서버는 특정한 값을 받아서 처리하게 된다. 이 소스에서 필자는 Pipe 의 간단한 프로토콜을 정의하였는데, 그것은 다음과 같다.
프로토콜 정의
[CMDS (정상적인 PIPE 패킷이라는 서명(sign)), 4바이트]
[명령, 4바이트]
[명령 번호, 4바이트]
[추가 정보 길이, 4바이트]
[추가 정보, 추가 정보 길이에 명시된 길이 ~ 버퍼의 최대 길이]
이 프로토콜에 맞는 형식을 갖춘 데이터들은 내부적으로 사용자가 지정한 함수 포인터를 호출한다. 그리고 마지막으로, 그렇게 호출된 함수의 반환값을 다시 클라이언트에 보내주는 것으로 서버는 하나의 패킷에 대한 처리를 마무리 하게 된다.
이 클래스를 사용하는 방법은 매우 간단하다.
먼저, 클래스를 선언한 후, StartPipeServer 함수를 호출해 주면 된다.
다음은 간단한 예제이다.
#include "PipeServer.h"
CPipeServer g_pipeServer;int WINAPI ProcessIO(DWORD dwCmd, DWORD dwCmdNumber, DWORD dwLen, char* lpszData, DWORD* pdwRetLen, char* lpszReturn)
{
char szMsg[1024];
sprintf(szMsg, "Cmd : %d, CmdNumber : %d, dwLen : %d, lpszData : %s",
dwCmd, dwCmdNumber, dwLen, lpszData );strcpy( lpszReturn, "ProcessIO 에서 처리한 내용! : " );
strcat( lpszReturn, szMsg );
*pdwRetLen = strlen(lpszReturn);return 0;
}
DWORD WINAPI ServiceExecutionThread(LPDWORD param)
{
g_pipeServer.StartPipeServer( "\\\\.\\pipe\\VistaSvcIPC", ProcessIO );
return 0;
}
이렇게 구성된 프로그램을 서비스로 만들고, 일반 권한 프로그램에서 이 서비스와 통신하게 할 수 있다. 클라이언트에 대한 코드는 아래와 같다.
void CNormalPrgDlg::OnButton1()
{
static BOOL bConnected = FALSE;if(bConnected) {
CString szText;
m_edt.GetWindowText( szText );char szBuffer[BUFSIZE] = { 0, };
char szRetData[BUFSIZE] = { 0, };
DWORD dwRetLen = 0;
strcpy(szBuffer, szText);
g_pipeClient.Send(1024, GetTickCount(), strlen(szBuffer)+1, szBuffer, &dwRetLen, szRetData);
m_lst.InsertString(0, szRetData);
} else {
bConnected = g_pipeClient.ConnectPipe("\\\\.\\pipe\\VistaSvcIPC");
}
}
이 예제가 동작하는 모습은 아래와 같다.
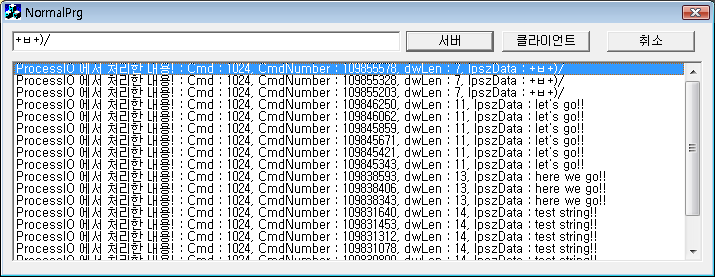
[그림2] 실제 IPC 예제 프로그램이 동작하는 화면
첨부된 파일의 소스는 서버와 클라이언트이며, MFC 를 기반으로 작성되어 있다.
korea 에 s/w 의 미래는 없다.
2008. 6. 2. 11:19
그들은 그들이 쓰는 s/w 가 얼마나 소중한지,
자신이 어떤 위치에 있는지,
어떻게 생각해야 하는지,
아주 기본적인 소양조차 아예없기 때문이다.
자신이 어떤 위치에 있는지,
어떻게 생각해야 하는지,
아주 기본적인 소양조차 아예없기 때문이다.
이미지!
2008. 5. 31. 14:49
